I talked many times about Health Checks in Contrail. Their primary goal is to verify the liveliness of a VMI. Health Checks can use BFD (faster but needs VNF to support it) or ICMP ( slower but any VNF supports it).
Simply checking whether a VMI is alive or not is not enough or, better, does not help us that much. We use health checks to trigger network adaptation in case of failures. The aim of health checks is to have an object that can detect a failure and trigger the network protocol into re-compute paths and avoid the failed entity. We want this process to be as fast as policy…and this depends on how fast the health check can detect a failure.
When we configure a Health Check, we need to set two main parameters: delay and retries. Delay sets the time between two consecutive “health check attempts” (let’s call them probes) while retries is the maximum number of failed probes before declaring the health check down.
With BFD, this is pretty straightforward. Delay is the “minimum-interval” while retries is the “multiplier”. Let’s assume we did set delay=500ms and retries=3. In this case, a BFD packet will be sent every 500ms and, after 3 consecutive losses, BFD session is declared down. As a consequence, it is pretty easy to conclude that convergence is 1.5 seconds.
Convergence time is retry*delay.
With ICMP, we would expect the same…i was expecting the same!
But it’s not 🙂 That’s why I thought to write this post…
An introductory note: relying on ICMP health check is never the best idea but there are some use-cases where this is the only option you have.
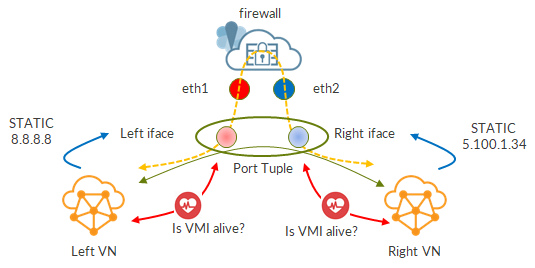
Here, my VNF did not support BFD so I had to move to ICMP. Moreover, I was in a service chain scenario, meaning I actually had 2 health checks: one on left interface, one on right interface.
First discovery I made: ICMP health checks do not support microseconds (or milliseconds) timers. This means the minimum configurable delay is 1 second.
For this reason, i configured some strict health checks parameters: delay equal to 1 second, retry equal to 1.
Considering this, my expectations were to have 1 second convergence…reasonable, right?
Instead, I saw 2 seconds or even 4 seconds loss. How is this possible? What’s wrong?
To find out more, I connected to the compute node where the monitored VNF was running.
By running
ps -ef | grep ping
I was able to detect the ping process created due to the health check.
And what a surprise!
root 959071 668165 0 09:29 ? 00:00:00 ping -c2 -W1 169.254.255.254
The ping uses mdata addresses (169.254.255.254) but this is not so important. What really plays a role here is the “-c2” parameter. That parameter means “send 2 ping packets”. But didn’t we configure retry=1? Yes…but that “-c2” is hardcoded, we cannot change it!
Here is the thing: the health check attempt, the probe, is actually 2 pings, always, period.
So how does the health check work? Contrail starts a probe, which is actually 2 pings, waits for one second (configured Delay value), then another probe starts. This means that every “probe cycle” takes 3 seconds: 2 seconds to send the pings (-c2) and 1 delay second.
What does this mean? If retry=1, then one probe must fail but one probe (just the pings) takes 2 seconds…minimum convergence is 2 seconds!
Let’s consider another example with retry=3 and delay=1. How long will it take to detect the failure? We have 2 full probe cycles (3 seconds each) plus one last probe (just the pings, 2 seconds). This makes a total of 8 seconds! Way more than the 3 seconds we might have imagined (assuming ICMP HC behaves like BFD HC, meaning convergence is delay*retry).
Knowing how ICMP HC actually works is fundamental in order to understand how fast failure detection should be. The risk is to think contrail is misbehaving, even if contrail is doing more than ok. Those 8 seconds are correct and they come from an internal contrail behavior that goes beyond the user and that is a bit…hidden 🙂 There’s nothing wrong; simply put, ICMP HC are, by design, even slower than what we thought 🙂
Let’s see a real example.
I had 2 HCs: HC_L for left interface, HC_R for right interface.
VNF ports wen down at 8:25:10.
Monitoring Introspect trace logs, we can check HC test results:
1591773910 714617 HealthCheckTrace: log = Instance for service tovb-nbp:juniper-project:HC_L interface tap9bcf6c9d-0e Received msg = Success file = controller/src/vnsw/agent/oper/health_check.cc line = 968 1591773910 714632 HealthCheckTrace: log = Instance for service tovb-nbp:juniper-project:HC_R interface tap31aa9467-f8 Received msg = Success file = controller/src/vnsw/agent/oper/health_check.cc line = 968 1591773913 719776 HealthCheckTrace: log = Instance for service tovb-nbp:juniper-project:HC_R interface tap31aa9467-f8 Received msg = Failure file = controller/src/vnsw/agent/oper/health_check.cc line = 968 1591773913 722575 HealthCheckTrace: log = Instance for service tovb-nbp:juniper-project:HC_L interface tap9bcf6c9d-0e Received msg = Failure file = controller/src/vnsw/agent/oper/health_check.cc line = 968
Timestamps can be converted to “human readable” date.
Moreover, in a timestamp like “1591773910714617”, the first 10 digits “1591773910” are enough as they give us seconds precision.
As you can see first even t is at “1591773910” while latest event is at “1591773913”, 3 seconds later.
To have full convergence, we have to wait for both HCs to fail. In this case, latest failure is for HC_L at 9:25:13.
We are consistent with what we have said before: convergence is in the order of a couple of seconds. We see 3 seconds but consider some extra time neede by contrail to react to a HC down event. This reaction means updating routing table (remove that VMI) and sending updates to all the compute nodes (xmpp).
I had an end-to-end flow between 192.168.100.3 and 192.168.200.3.
I captured traffic on the left interface (IP. 192.168.100.4). On that VMI we have both user traffic (100.3 200.3) and ICMP HC traffic (100.2 100.4)
Here is what I did see (mind the timestamps ;)):
initially, both user traffic and hc traffic are fine...
09:25:09.077133 IP 192.168.100.3 > 192.168.200.3: ICMP echo request, id 43265, seq 1, length 64
09:25:09.077420 IP 192.168.200.3 > 192.168.100.3: ICMP echo reply, id 43265, seq 1, length 64
09:25:09.714136 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 8086, seq 1, length 64
09:25:09.714221 IP 192.168.100.4 > 192.168.100.2: ICMP echo reply, id 8086, seq 1, length 64
09:25:10.077242 IP 192.168.100.3 > 192.168.200.3: ICMP echo request, id 43265, seq 2, length 64
09:25:10.077664 IP 192.168.200.3 > 192.168.100.3: ICMP echo reply, id 43265, seq 2, length 64
09:25:10.714048 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 8086, seq 2, length 64
09:25:10.714090 IP 192.168.100.4 > 192.168.100.2: ICMP echo reply, id 8086, seq 2, length 64
from here, failure is on
09:25:11.077357 IP 192.168.100.3 > 192.168.200.3: ICMP echo request, id 43265, seq 3, length 64
user traffic keeps coming here as HC is still up
09:25:11.719284 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 8090, seq 1, length 64
!!! first ICMP HC with no reply
09:25:12.077439 IP 192.168.100.3 > 192.168.200.3: ICMP echo request, id 43265, seq 4, length 64
09:25:12.720171 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 8090, seq 2, length 64
!!! second ICMP HC with no reply
here i missed 2 ping hc packets (but 2 make one probe so here is the failure with retry 1)
this interval is routing convergence time -> at least 350 ms
in this interval user traffic still comes here as contrail is still converging
REMEMBER: convergence is HC detection time + contrail processing time + contrail signalling time
09:25:13.077537 IP 192.168.100.3 > 192.168.200.3: ICMP echo request, id 43265, seq 5, length 64
from here swichover, consistent with hc going down
NO MORE user traffic!
only failing HC traffic
09:25:15.725143 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 8097, seq 2, length 64
09:25:18.730715 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 8101, seq 2, length 64
09:25:21.735123 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 8107, seq 2, length 64
09:25:24.740284 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 8111, seq 2, length 64
All clear right?
Yes…but, before, I said i saw even bigger losses…what’s wrong?
Let’s check this other example.
VNF interfaces go down at 9:05:19.
Traces show this:
1591776319 765166 HealthCheckTrace: log = Instance for service tovb-nbp:juniper-project:HC_L interface tap9bcf6c9d-0e Received msg = Success file = controller/src/vnsw/agent/oper/health_check.cc line = 968 1591776321 764515 HealthCheckTrace: log = Instance for service tovb-nbp:juniper-project:HC_R interface tap31aa9467-f8 Received msg = Success file = controller/src/vnsw/agent/oper/health_check.cc line = 968 1591776322 769401 HealthCheckTrace: log = Instance for service tovb-nbp:juniper-project:HC_L interface tap9bcf6c9d-0e Received msg = Failure file = controller/src/vnsw/agent/oper/health_check.cc line = 968 1591776324 769279 HealthCheckTrace: log = Instance for service tovb-nbp:juniper-project:HC_R interface tap31aa9467-f8 Received msg = Failure file = controller/src/vnsw/agent/oper/health_check.cc line = 968
Left HC goes down at 9:05:22 while right HC goes down at 9:05:24.
In this case, simply, we were unlucky. We are in a service chain scenario with two HC objects. Those objects are independent one from another.
In the previous example, luckily, they were synched; this time they were desynched…and this led to higher convergence.
Mistery solved!
Let’s check captured packets again
initially, everything ok
10:05:19.610811 IP 192.168.100.3 > 192.168.200.3: ICMP echo request, id 43521, seq 10, length 64
10:05:19.611098 IP 192.168.200.3 > 192.168.100.3: ICMP echo reply, id 43521, seq 10, length 64
last user trf ok
10:05:19.764747 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 12129, seq 2, length 64
10:05:19.764823 IP 192.168.100.4 > 192.168.100.2: ICMP echo reply, id 12129, seq 2, length 64
last left HC ping ok
10:05:20.610907 IP 192.168.100.3 > 192.168.200.3: ICMP echo request, id 43521, seq 11, length 64
10:05:20.768880 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 12135, seq 1, length 64
!!! first miss
10:05:21.611041 IP 192.168.100.3 > 192.168.200.3: ICMP echo request, id 43521, seq 12, length 64
10:05:21.769057 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 12135, seq 2, length 64
!!! second miss
routing convergence
this is the last user traffic packets seen here
10:05:22.611109 IP 192.168.100.3 > 192.168.200.3: ICMP echo request, id 43521, seq 13, length 64
no more user traffic here here
but no overall convergence!
REMEMBER: right HC failed after left HC. We do not see it here but packets are kep coming on right interface. Left HC is down so this VMI was removed from routing table but right HC is still up (will go down 2 seconds later). During those 2 seconds return packets are still sent towards VNF right interface!
end-to-end depends on right interfaces as well (we saw it goes down @ 25)
what matters is that after 22 i do not see upstream packets here. This means left HC worked fine; traffic is blocked on left interface...but overall convergence is the sum of 2 independent HC objects!
10:05:24.772939 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 12139, seq 2, length 64
10:05:27.778739 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 12143, seq 2, length 64
10:05:30.781972 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 12149, seq 2, length 64
10:05:33.786539 IP 192.168.100.2 > 192.168.100.4: ICMP echo request, id 12153, seq 2, length 64
Please, be aware that this consideration is true for BFD as well. The difference is that, using microsends timers (and not having hidden settings like -c2 increasing convergence by design) the desynch effect weighs less and we tend not to observe it!
In any case, even here, contrail was working fine, nothing wrong!
So what do we take home from this? Mainly two things…
One: know the HC implementation! The nasty “-c2” is key to lose your head about slow ICMP HC convergence.
Two: every object is independent! IF convergence relies on multiple HC objects, you need all of them to fail to see the desired effects.
Now you know it 🙂
Ciao
IoSonoUmberto