Normally, if you look at Contrail architectures, you will a MX being used as L3 SDN Gateway. That MX exchanges inet-vpn routes with Contrail and at the same time is part of the network backbone. This means he is part of the backbone IGP (plus LSP domain via RSVP or LDP) and is the “access point” for VPNs (he is a PE as well) .
Anyhow, sometimes, a MX (or a proper router) is not available or is not a high-end device able to take the additional burden of being a SDN gateway.
This might be the case of remote POPs in an edge compute scenario. In those small locations we already have a router dealing with the edge (and metro) of the network. It might happen that a small DC, hosting “remote” computes will be attached to that router but that same device cannot act as SDN gateway.
There might be multiple reasons for this. As said, it could not cope with the new burden given by enabling these new functionalities. Or, simply, the device is old and does not support certain technologies (e.g. MPLSoUDP). And of course, there might be economical reasons, as always!
In this case, we might bring the SDN GW role inside the DC and have QFX spines acting as SDN GWs.
To better understand how this might work, I built a small lab:
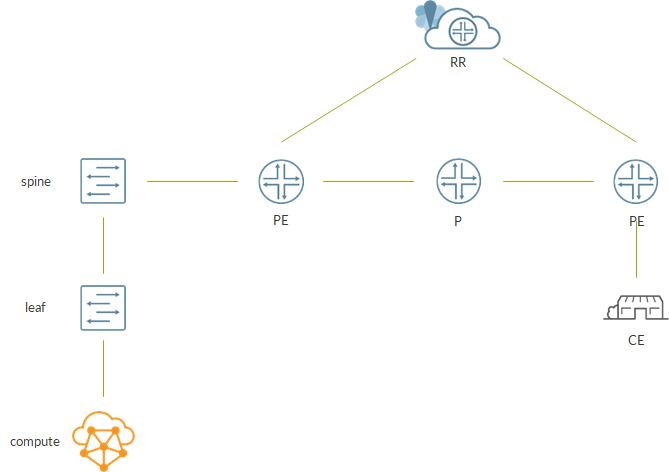
Overall, it is pretty straightforward; we have a small DC represented by a compute node and a 1×1 IP Fabric.
Spine is connected to a router which is part of the backbone. This router is a PE as, through a MPLS backbone, it can reach remote PEs. Signaling inside the backbone happens via a Route Reflector.
As said, we elect the spine as our SDN GW. The main goal here is to enable communications between a VM hosted on the compute node and the CE.
This use-case is straightforward if the router was used as SDN GW; it would take care fo terminating the MPLSoUDP and “translate” it into a MPLSoMPLS one.
Now, this must be done by the spine! In the lab, I used a vQFX which is a virtual version of a QFX 10k so we should expect this solution to work fine on physical QFX 10k as well.
Moving the SDN GW to the spine has some implications that we have to take care of. First, the BGP session between the SDN GW and Contrail is normally eBGP. Here, as spine and contrail share the same AS, the session will be internal. Anyhow, this is a small change.
The big difference is that the spine is not part of the backbone so it does not a “leg” on the mpls domain by default. This might represent a problem as the SDN GW is the one enforcing the MPLSoUDP to MPLSoMPLS translation!
One obvious solution would be to extend the MPLS domain up to the spine but this might not be possible, for instance, for organizational reasons (backbone team is not the dc team).
Who can help us here is, once again, BGP. MPLS information is normally advertised via LDP or RSVP; LDP is the label distribution protocol I did use in the backbone. Anyhow, BGP can assign labels to route and advertise them as well. This is achieved by using family labelled-unicast (BGP-LU). This way, the spine can send MPLS packets without being part of the backbone.
Here is how the overall “control plane” will look like:
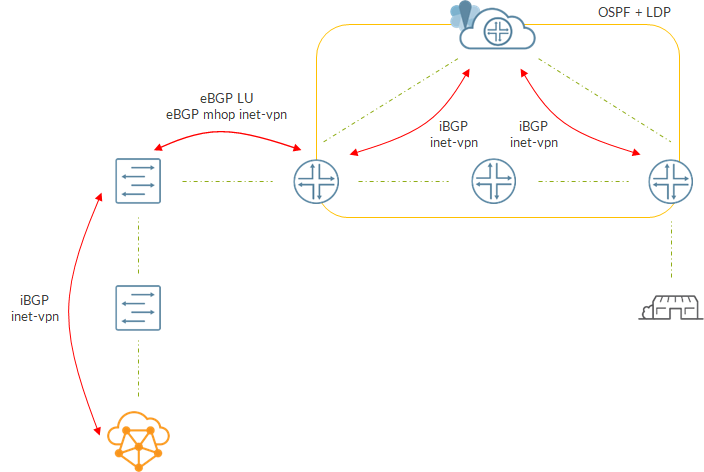
Spine has an iBGP session with Contrail to get VM routes.
At the same time, spine talks BGP with the directly connected router. Actually, there are 2 eBGP sessions here. One session is interface based and is used to exchange LU information. Each device advertises its loopback to its neighbor. The second session is a multihop session between loopbacks used to exchange inet-vpn routes. Being eBGP, the next-hop of the routes will be set to the loopback of the advertising device. Neighbor will be able to resolve that next-hop as it has a route towards the peer’s loopback in inet.3 (result of BGP LU exchange😉).
Inside the core, we have standard signaling with PEs using iBGP to talk to a Route Reflector.
The resulting data path is the following:
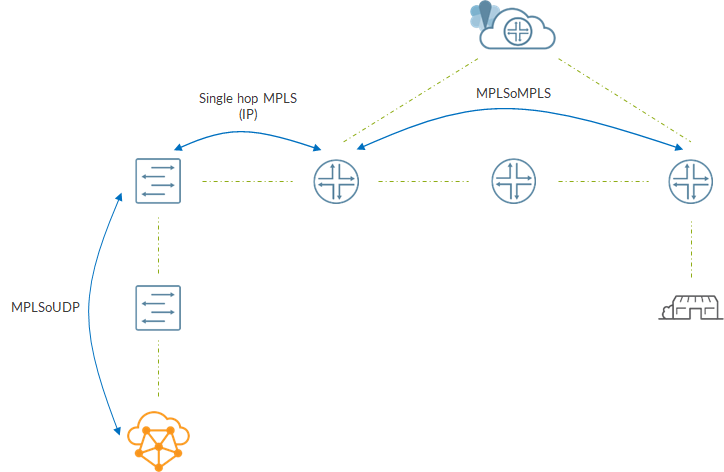
Between compute and spine we have a MPLSoUDP tunnel.
Spine removes the MPLS label and, based on information inside mpls.0, swaps the label and sends the packet to the local PE. Here, there will be no stacked label, just the service label as the spine-PE “lsp” is single hop so it will be just IP.
At the PE, another lookup happens inside mpls.0; this time service label is swapped and a transport label (lsp from PE to PE) is pushed. From here, it is business as usual 😊
Now, let’s see the most relevant configuration aspects of this scenario.
Contrail was created as an all-in-one node using ansible deployer. As I have already dealt with this topic in other occasions, I will skip it and give it for granted. Just to give more context, I created a K8s driven cluster as, being my compute node a VM itself, it is easier to run containers than VMs (which would be nested VMs!).
Leaf is a standard leaf with eBGP underlay session (inet) and iBGP overlay session (evpn). The ERB model is used. As a consequence, the overlay iBGP session is basically useless in this scenario. I configured it in order to mimic a real fabric as much as possible.
I will mainly focus on the spine.
The spine has eBGP underlay session and iBGP overlay session with the leaf.
Over the underlay session, the spine learns contrail control data network:
root@spine> show route receive-protocol bgp 192.168.2.0
inet.0: 16 destinations, 16 routes (16 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 1.1.1.1/32 192.168.2.0 65501 I
* 192.168.1.0/24 192.168.2.0 65501 I
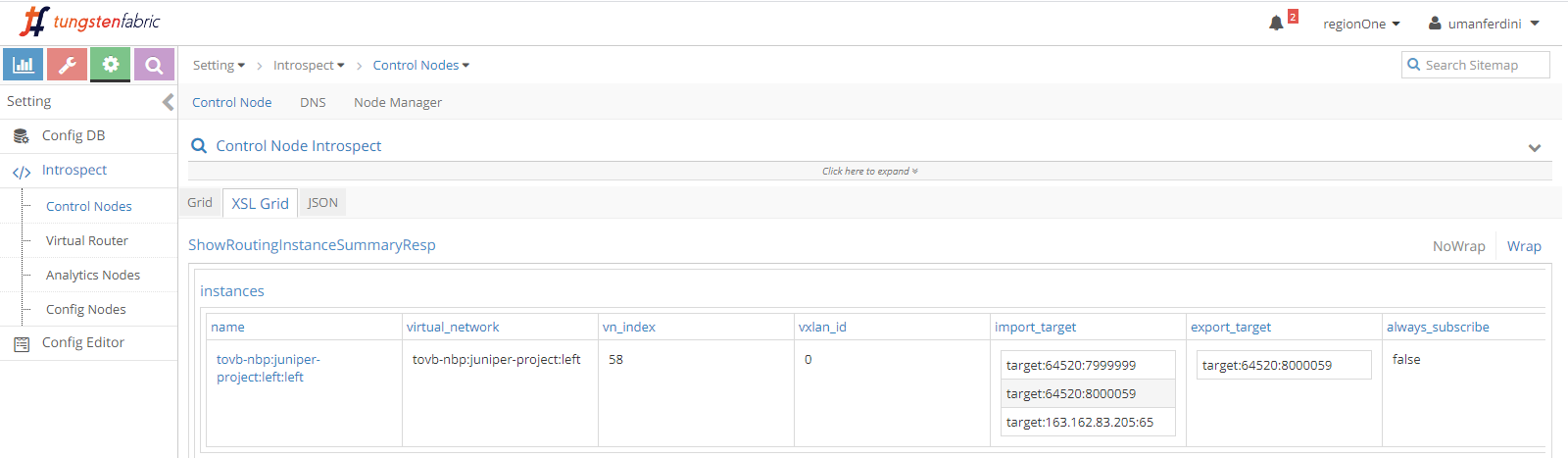
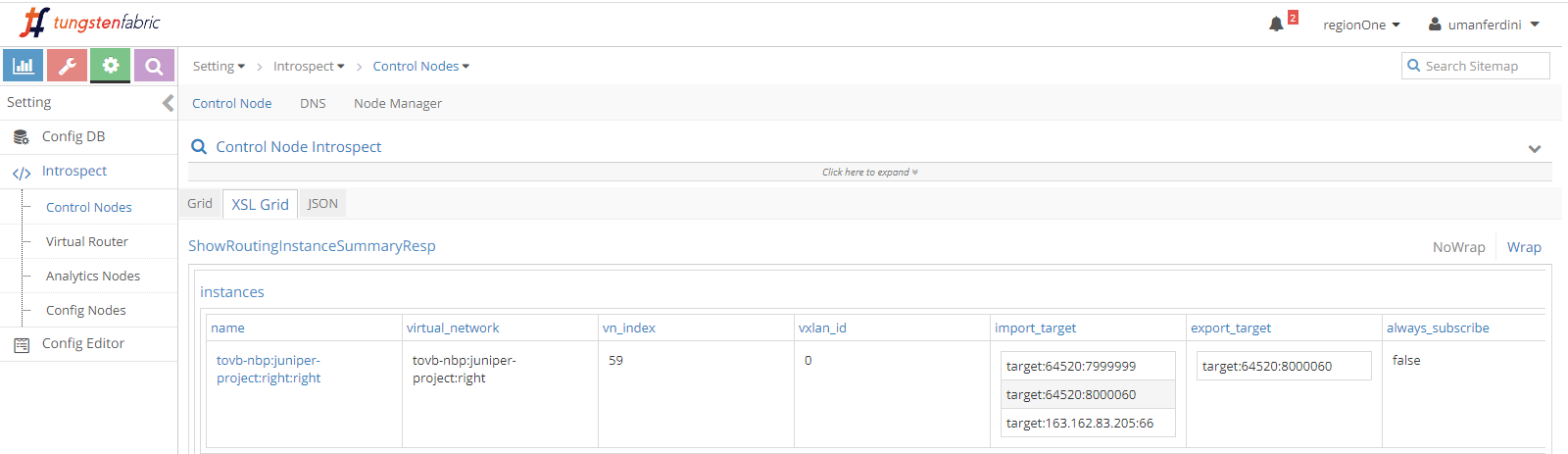
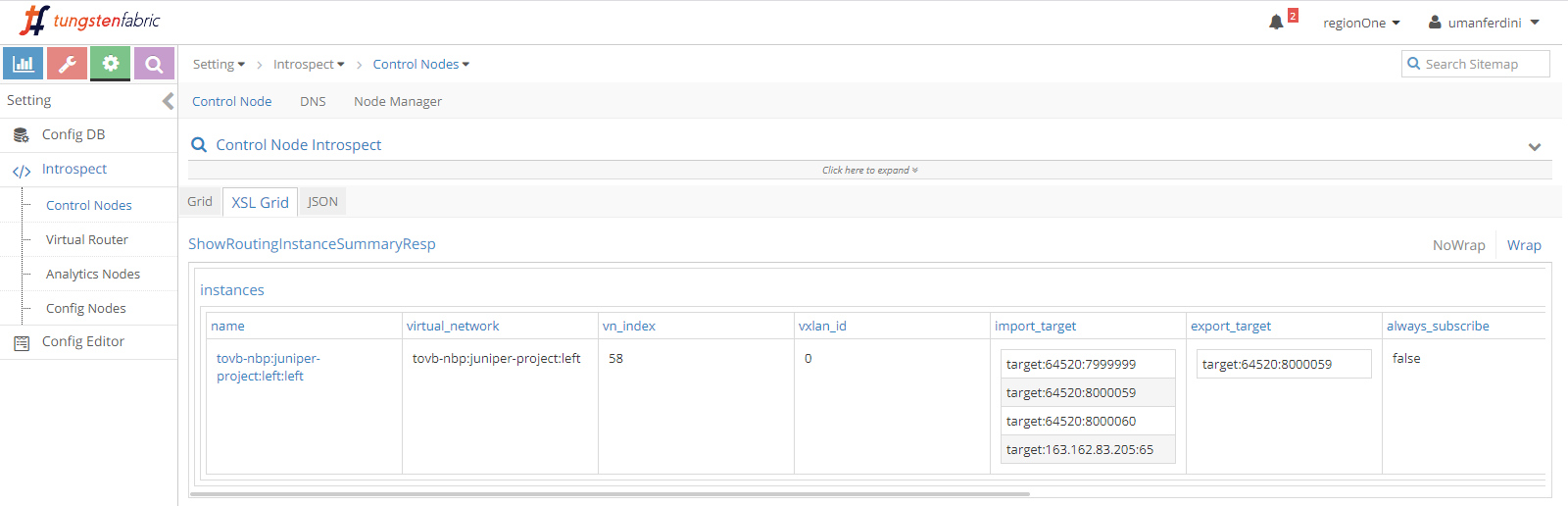
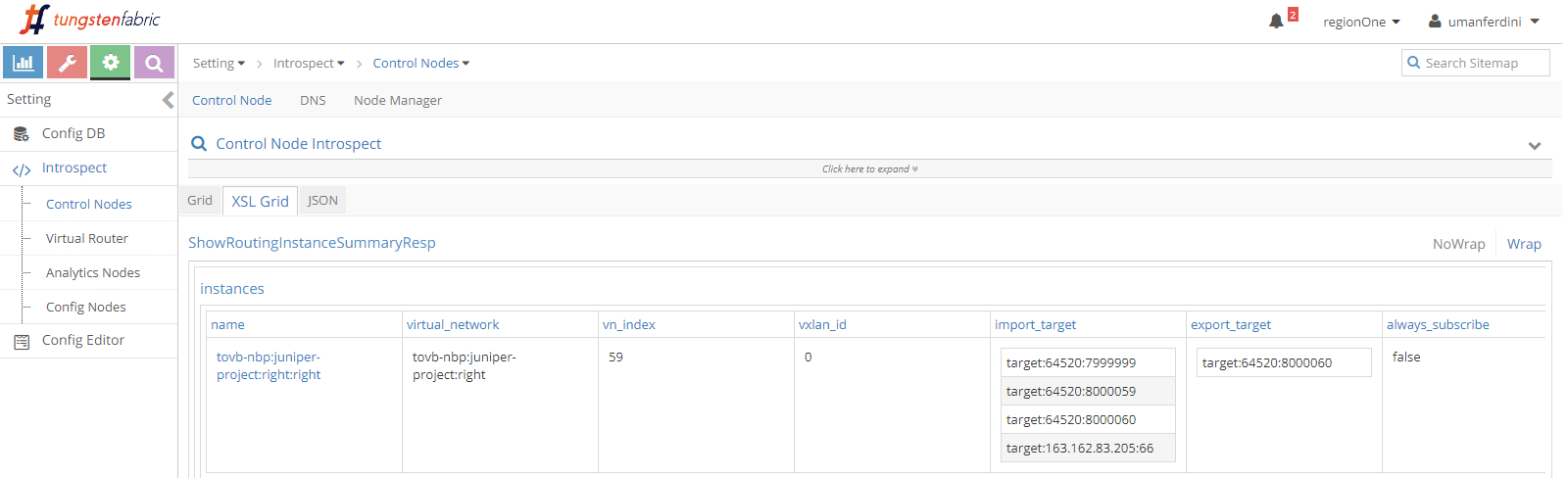
Contrail control+data network is 192.168.1.0/24.
That same network is the destination network of our dynamic tunnels:
set routing-options dynamic-tunnels contrail source-address 2.2.2.2
set routing-options dynamic-tunnels contrail udp
set routing-options dynamic-tunnels contrail destination-networks 192.168.1.0/24
Next, we have the iBGP session with the Contrail controller (in this case that address is also the compute address as I have an all-in-one setup):
set protocols bgp group contrail type internal
set protocols bgp group contrail multihop ttl 10
set protocols bgp group contrail local-address 2.2.2.2
set protocols bgp group contrail family inet-vpn unicast
set protocols bgp group contrail export mplsoudp
set protocols bgp group contrail neighbor 192.168.1.3
set protocols bgp group contrail vpn-apply-export
set policy-options policy-statement mplsoudp term vpn from family inet-vpn
set policy-options policy-statement mplsoudp term vpn then community add mplsoudp
set policy-options community mplsoudp members 0x030c:65512:13
As you can see, apart from being an internal session, this is a standard sdn gw configuration!
Also, remember to enable family mpls on the interface towards Contrail:
set interfaces xe-0/0/0 unit 0 family mpls
Now, let’s move to the LU session:
set protocols bgp group core-lu type external
set protocols bgp group core-lu family inet labeled-unicast resolve-vpn
set protocols bgp group core-lu export exp-lu
set protocols bgp group core-lu peer-as 100
set protocols bgp group core-lu neighbor 192.168.3.1
Session is interface based. We do export our loopbck:
set interfaces lo0 unit 0 family inet address 2.2.2.2/32
set policy-options policy-statement exp-lu term lo0 from interface lo0.0
set policy-options policy-statement exp-lu term lo0 then accept
set policy-options policy-statement exp-lu then reject
On the PE we have something similar:
set protocols bgp group lu type external
set protocols bgp group lu family inet labeled-unicast resolve-vpn
set protocols bgp group lu export exp-lu
set protocols bgp group lu peer-as 65512
set protocols bgp group lu neighbor 192.168.3.0
set policy-options policy-statement exp-lu term lo0 from interface lo0.0
set policy-options policy-statement exp-lu term lo0 then accept
set policy-options policy-statement exp-lu then reject
Please, have a look at this line:
set protocols bgp group lu family inet labeled-unicast resolve-vpn
This tells Junos to use that route to resolve vpn routes. This means placing those routes inside inet.3.
Spine receives PE loopback over this session:
root@spine> show route receive-protocol bgp 192.168.3.1 table inet.0 extensive
inet.0: 16 destinations, 16 routes (16 active, 0 holddown, 0 hidden)
* 3.3.3.3/32 (1 entry, 1 announced)
Accepted
Route Label: 3
Nexthop: 192.168.3.1
AS path: 100 I
Entropy label capable, next hop field matches route next hop
Notice, advertised label is 3 as this is a single hop path.
The route is placed I ninet.3 as well:
root@spine> show route table inet.3
inet.3: 3 destinations, 3 routes (3 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
3.3.3.3/32 *[BGP/170] 1d 21:24:56, localpref 100
AS path: 100 I, validation-state: unverified
> to 192.168.3.1 via xe-0/0/1.0
On spine, remember to enable mpls where needed:
set interfaces xe-0/0/0 unit 0 family mpls
set interfaces xe-0/0/1 unit 0 family mpls
set protocols mpls no-cspf
set protocols mpls interface xe-0/0/2.0
set protocols mpls interface xe-0/0/1.0
A loopback based bgp session is established to exchange inet-vpn routes:
set protocols bgp group core-inetvpn type external
set protocols bgp group core-inetvpn multihop ttl 3
set protocols bgp group core-inetvpn local-address 2.2.2.2
set protocols bgp group core-inetvpn family inet-vpn unicast
set protocols bgp group core-inetvpn peer-as 100
set protocols bgp group core-inetvpn neighbor 3.3.3.3
This is enough to have everything in place!
We do not analyze other devices into detail as they are configured so to implement a classic MPLS backbone.
Follow the path
What is more interesting is to follow packet flow from Contrail to remote PE.
CE is connected to PE over a subnet with address 192.168.6.0/24.
Remote PE announces this route to the RR which, in turn, advertises it to the local PE.
At this point, the local PE announces the route to the spine over the eBGP multihop inte-vpn session:
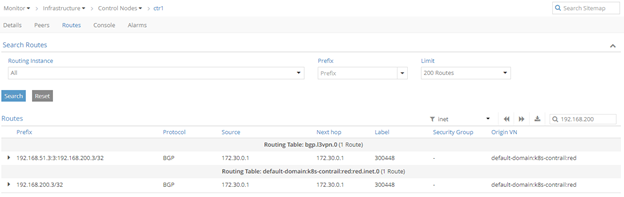
root@spine> show route receive-protocol bgp 3.3.3.3 table bgp.l3vpn.0 extensive
bgp.l3vpn.0: 5 destinations, 5 routes (5 active, 0 holddown, 0 hidden)
* 5.5.5.5:10:192.168.6.0/24 (1 entry, 1 announced)
Accepted
Route Distinguisher: 5.5.5.5:10
VPN Label: 300544
Nexthop: 3.3.3.3
AS path: 100 I
Communities: target:65512:100
PE uses label 300544.
Spine announces this route to Contrail (obviouslu Contrail has a virtual network with a matching route target):
root@spine> show route advertising-protocol bgp 192.168.1.3 table bgp.l3vpn.0 extensive
bgp.l3vpn.0: 5 destinations, 5 routes (5 active, 0 holddown, 0 hidden)
* 5.5.5.5:10:192.168.6.0/24 (1 entry, 1 announced)
BGP group contrail type Internal
Route Distinguisher: 5.5.5.5:10
VPN Label: 32
Nexthop: Self
Flags: Nexthop Change
Localpref: 100
AS path: [65512] 100 I
Communities: target:65512:100 encapsulation:mpls-in-udp(0xd)
Label 32 is used on this path.
Inside Contrail we have a VM with ip 192.168.123.3.
That VM is reachable via a MPLSoUDP tunnel:
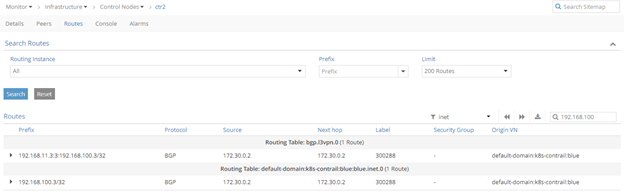
root@spine> show route table bgp.l3vpn.0 192.168.123.3/32
bgp.l3vpn.0: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
192.168.1.3:4:192.168.123.3/32
*[BGP/170] 00:00:15, MED 100, localpref 200, from 192.168.1.3
AS path: ?, validation-state: unverified
> to 192.168.2.0 via xe-0/0/0.0
root@spine> show route table bgp.l3vpn.0 192.168.123.3/32 extensive | match Tunnel
Next hop type: Tunnel Composite
Tunnel type: UDP, nhid: 0, Reference-count: 4, tunnel id: 0
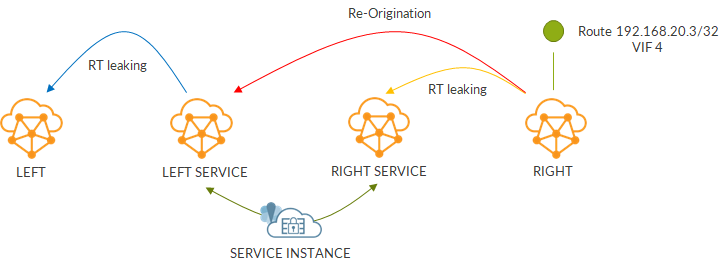
As seen before, contrail encapsulates packets from VM in MPLSoUDP tunnels using label 32.
When frames arrive at the spine, a lookup is performed inside mpls.0:
root@spine> show route table mpls.0 label 32
mpls.0: 12 destinations, 12 routes (12 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
32 *[VPN/170] 1d 21:48:00, metric2 0, from 3.3.3.3
> to 192.168.3.1 via xe-0/0/1.0, Swap 300544
Label is swapped to 300544. That is the service label advertised by the PE. As already mentioned, there is no double label as there is only a single hop between spine and PE.
This is how MPLSoUDP transitions to MPLSoMPLS (or just MPLS here 😊).
Let’s see check the other direction.
PE will send packets using this service label:
root@spine> show route advertising-protocol bgp 3.3.3.3 192.168.123.3/32 extensive
bgp.l3vpn.0: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden)
* 192.168.1.3:4:192.168.123.3/32 (1 entry, 1 announced)
BGP group core-inetvpn type External
Route Distinguisher: 192.168.1.3:4
VPN Label: 51
Nexthop: Self
Flags: Nexthop Change
AS path: [65512] ?
Communities: target:65512:100 target:65512:8000007 encapsulation:unknown(0x2) encapsulation:mpls-in-udp(0xd) mac-mobility:0x0 (sequence 1) router-mac:56:68:a6:6f:13:5f unknown type 0x8004:0xffe8:0x7a120b unknown type 0x8071:0xffe8:0xb unknown type 0x8084:0xffe8:0xff0004 unknown type 0x8084:0xffe8:0x1030000 unknown type 0x8084:0xffe8:0x1040000
Let’s check what spine does with label 51:
root@spine> show route table mpls.0 label 51
mpls.0: 12 destinations, 12 routes (12 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
51 *[VPN/170] 00:20:12, metric2 0, from 192.168.1.3
> to 192.168.2.0 via xe-0/0/0.0, Swap 40
root@spine> show route table mpls.0 label 51 extensive | grep "Tunnel Type"
Tunnel type: UDP, nhid: 0, Reference-count: 4, tunnel id: 0
This is the MPLSoMPLS to MPLSoUDP transition.
Label 40, of course, is not random. It is the label advertised by Contrail:
root@spine> show route receive-protocol bgp 192.168.1.3 192.168.123.3/32 extensive
bgp.l3vpn.0: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden)
* 192.168.1.3:4:192.168.123.3/32 (1 entry, 1 announced)
Accepted
Route Distinguisher: 192.168.1.3:4
VPN Label: 40
Nexthop: 192.168.1.3
MED: 100
Localpref: 200
AS path: ?
Communities: target:65512:100 target:65512:8000007 encapsulation:unknown(0x2) encapsulation:mpls-in-udp(0xd) mac-mobility:0x0 (sequence 1) router-mac:56:68:a6:6f:13:5f unknown type 0x8004:0xffe8:0x7a120b unknown type 0x8071:0xffe8:0xb unknown type 0x8084:0xffe8:0xff0004 unknown type 0x8084:0xffe8:0x1030000 unknown type 0x8084:0xffe8:0x1040000
Remember, as we have eBGP between spine and PE, they both rewrite the next-hop (to their loopback) when sending inet-vpn routes.
As a result, on the PE we have a swap-push operation:
root@pe1> show route table mpls.0 label 300544
mpls.0: 13 destinations, 13 routes (13 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
300544 *[VPN/170] 1d 22:12:42, metric2 1, from 10.10.10.10
> to 192.168.4.1 via ge-0/0/1.0, Swap 16, Push 299824(top)
From this point, it is business as usual 😊
Let’s check how PE advertises VM route to RR:
root@pe1> show route advertising-protocol bgp 10.10.10.10 192.168.123.3/32 extensive
bgp.l3vpn.0: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden)
* 192.168.1.3:4:192.168.123.3/32 (1 entry, 1 announced)
BGP group rr type Internal
Route Distinguisher: 192.168.1.3:4
VPN Label: 300928
Nexthop: Self
Route distinguisher is a Contrail address but Protocol next hop is rewritten (next hop self). This means that, to remote PEs, all VM routes appear to be behind this PE.
That’s it: vQFX outside the backbone but still able to be a SDN GW and use Inter AS option B and mpls!
Of course, this is just one possible design. Alternatives are available!
Ciao
IoSonoUmberto