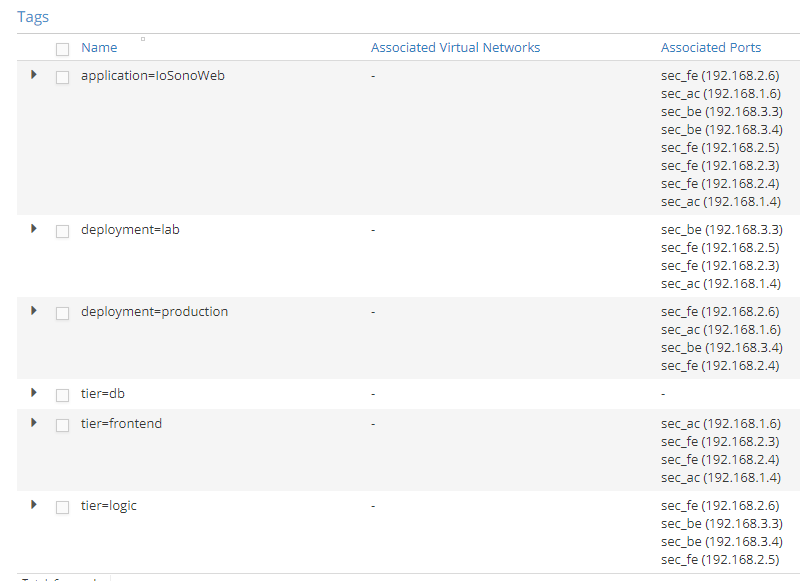
Junos filters are well known and widely used in order to control which traffic to accept on a device.
Normally, we crate a filter and apply it to an interface.
Alternatively, we might create an interface-specific filter and apply it to multiple interfaces and get per-interface counters.
There is another option where we configure a filter at a “higher level” (we will see what I mean) and control traffic to be accepted/discarded/counted based on so-called interface groups.
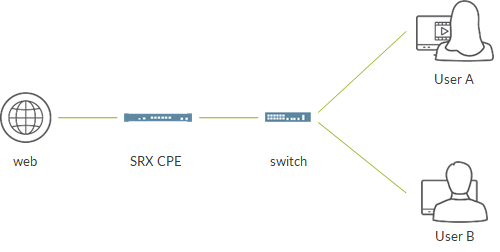
To understand how this works, let’s consider the following topology:

We are going to focus on the router at the top.
That router as 3 interfaces:
- one interface is assigned to group 1 (blue)
- one interface is assigned to group 2 (red)
- one interface does not belong to any group
Let’s have a look at router basic configuration.
set interfaces ge-0/0/0 unit 0 family inet filter group 1
set interfaces ge-0/0/0 unit 0 family inet address 192.168.0.1/31
set interfaces ge-0/0/1 unit 0 family inet filter group 2
set interfaces ge-0/0/1 unit 0 family inet address 192.168.1.1/31
set interfaces ge-0/0/2 unit 0 family inet address 192.168.2.1/31
set interfaces lo0 unit 0 family inet address 10.10.10.10/32Notice, interfaces ge-0/0/0 and ge-0/0/1 are assigned to groups.
This is a small lab; in a real environment the idea is to have many interfaces mapped to few groups.
As said before, ge-0/0/2 is not assigned to any group.
Next, we run OSPF and BGP over those interfaces:
set routing-options autonomous-system 100
set protocols bgp group ibgp type internal
set protocols bgp group ibgp local-address 10.10.10.10
set protocols bgp group ibgp neighbor 1.1.1.1
set protocols bgp group ibgp neighbor 2.2.2.2
set protocols bgp group ibgp neighbor 3.3.3.3
set protocols ospf area 0.0.0.0 interface lo0.0 passive
set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 interface-type p2p
set protocols ospf area 0.0.0.0 interface ge-0/0/1.0 interface-type p2p
set protocols ospf area 0.0.0.0 interface ge-0/0/2.0 interface-type p2pNow, time to build the filter:
set firewall family inet filter filter-group term no-icmp from interface-group 2
set firewall family inet filter filter-group term no-icmp from protocol icmp
set firewall family inet filter filter-group term no-icmp then count no-icmp
set firewall family inet filter filter-group term no-icmp then discard
set firewall family inet filter filter-group term no-bgp from interface-group 1
set firewall family inet filter filter-group term no-bgp from protocol tcp
set firewall family inet filter filter-group term no-bgp from port 179
set firewall family inet filter filter-group term no-bgp then count no-bgp
set firewall family inet filter filter-group term no-bgp then discard
set firewall family inet filter filter-group term no-ssh from interface-group 2
set firewall family inet filter filter-group term no-ssh from protocol tcp
set firewall family inet filter filter-group term no-ssh from port 22
set firewall family inet filter filter-group term no-ssh then count no-ssh
set firewall family inet filter filter-group term no-ssh then discard
set firewall family inet filter filter-group term no-telnet from interface-group 1
set firewall family inet filter filter-group term no-telnet from protocol tcp
set firewall family inet filter filter-group term no-telnet from port 23
set firewall family inet filter filter-group term no-telnet then count no-telnet
set firewall family inet filter filter-group term no-telnet then discard
set firewall family inet filter filter-group term default then count default
set firewall family inet filter filter-group term default then acceptLet’s analyze term no-icmp. Understanding how it works will help us getting familiar with the whole mechanism:
set firewall family inet filter filter-group term no-icmp from interface-group 2
set firewall family inet filter filter-group term no-icmp from protocol icmp
set firewall family inet filter filter-group term no-icmp then count no-icmp
set firewall family inet filter filter-group term no-icmp then discardThe goal if this term is to discard icmp packets…but not any icmp packets, only packets entering interfaces belonging to group 2. In our scenario, only packet coming from ge-0/0/1.
Last, we need to apply this filter. As said, before, we do this at a “higher level”, not on one or more specific interfaces:
set forwarding-options family inet filter input filter-groupDevice is ready, time to verify things are working as expected.
Let’s start from ospf. Our filter tells nothing about OSPF so it should work on all the interface:
root@star_re> show ospf neighbor
Address Interface State ID Pri Dead
192.168.0.0 ge-0/0/0.0 Full 1.1.1.1 128 39
192.168.1.0 ge-0/0/1.0 Full 2.2.2.2 128 35
192.168.2.0 ge-0/0/2.0 Full 3.3.3.3 128 32BGP instead, is blocked on group 1 (ge-0/0/0, affecting session to 1.1.1.1):
root@star_re> show bgp summary
Threading mode: BGP I/O
Groups: 1 Peers: 3 Down peers: 1
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet.0
0 0 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
1.1.1.1 100 0 0 0 1 2:09:01 Connect
2.2.2.2 100 309 307 0 0 2:17:42 0/0/0/0 0/0/0/0
3.3.3.3 100 279 277 0 1 2:03:53 0/0/0/0 0/0/0/0What about ICMP?
Interface ge-0/0/1 (group 2, connecting to MX2) should discard packets.
MX2 cannot ping anybody:
root@mx2_re> ping 10.10.10.10
PING 10.10.10.10 (10.10.10.10): 56 data bytes
^C
--- 10.10.10.10 ping statistics ---
3 packets transmitted, 0 packets received, 100% packet loss
root@mx2_re> ping 1.1.1.1
PING 1.1.1.1 (1.1.1.1): 56 data bytes
^C
--- 1.1.1.1 ping statistics ---
3 packets transmitted, 0 packets received, 100% packet lossMX1 can ping anyone but MX2:
root@mx1_re> ping 10.10.10.10
PING 10.10.10.10 (10.10.10.10): 56 data bytes
64 bytes from 10.10.10.10: icmp_seq=0 ttl=64 time=4.571 ms
64 bytes from 10.10.10.10: icmp_seq=1 ttl=64 time=9.218 ms
^C
--- 10.10.10.10 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max/stddev = 4.571/6.894/9.218/2.324 ms
root@mx1_re> ping 3.3.3.3
PING 3.3.3.3 (3.3.3.3): 56 data bytes
64 bytes from 3.3.3.3: icmp_seq=0 ttl=63 time=39.973 ms
64 bytes from 3.3.3.3: icmp_seq=1 ttl=63 time=6.027 ms
^C
--- 3.3.3.3 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max/stddev = 6.027/23.000/39.973/16.973 ms
root@mx1_re> ping 2.2.2.2
PING 2.2.2.2 (2.2.2.2): 56 data bytes
^C
--- 2.2.2.2 ping statistics ---
3 packets transmitted, 0 packets received, 100% packet lossThis is correct as echo replies from MX2 are discarded by our filter.
This tells us that our filter acts on both traffic to the RE and transit traffic.
Similar results for telnet (blocked on group 1, ge-0/0/0):
root@mx1_re> telnet 10.10.10.10
Trying 10.10.10.10...
^C
root@mx1_re> telnet 2.2.2.2
Trying 2.2.2.2...
^C
root@mx2_re> telnet 10.10.10.10
Trying 10.10.10.10...
Connected to 10.10.10.10.
Escape character is '^]'.
login:
telnet> q
Connection closed.
root@mx2_re> telnet 1.1.1.1
Trying 1.1.1.1...
^CPlease notice, telnet is blocked in any direction (MX1 -> MX2 and MX2 -> MX1). This is because the filter uses “from port 22”. We might allow a specific direction by changing the filter to something like “from destination-port 23” or “from source-port 23”.
We omit ssh verification as the mechanism is the same and should be clear by now 🙂
Of course, we can check counters to know how much traffic we discarded:
root@star_re# run show firewall
Filter: __default_bpdu_filter__
Filter: filter-group
Counters:
Name Bytes Packets
default 9088126 45002
no-bgp 89871 1559
no-icmp 2016 24
no-ssh 688 12
no-telnet 624 10Counters are aggregate ones; we do not have per-interface data.
Before concluding, there is still one thing worth looking at.
With the above examples, we have seen filter acts on both transit traffic and traffic destined to the RE.
Let’s change the config:
root@star_re# show forwarding-options
family inet {
filter {
input filter-group;
}
}
[edit]
root@star_re# delete forwarding-options
[edit]
root@star_re# set interfaces lo0.0 family inet filter input filter-group
[edit]
root@star_re# commit
commit completeProtocols look like before:
root@star_re> show ospf neighbor
Address Interface State ID Pri Dead
192.168.0.0 ge-0/0/0.0 Full 1.1.1.1 128 38
192.168.1.0 ge-0/0/1.0 Full 2.2.2.2 128 33
192.168.2.0 ge-0/0/2.0 Full 3.3.3.3 128 37
root@star_re> show bgp summary
Threading mode: BGP I/O
Groups: 1 Peers: 3 Down peers: 1
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet.0
0 0 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
1.1.1.1 100 0 0 0 1 2:20:41 Active
2.2.2.2 100 335 333 0 0 2:29:22 0/0/0/0 0/0/0/0
3.3.3.3 100 305 303 0 1 2:15:33 0/0/0/0 0/0/0/0Let’s try icmp:
root@mx2_re> ping 10.10.10.10
PING 10.10.10.10 (10.10.10.10): 56 data bytes
^C
--- 10.10.10.10 ping statistics ---
4 packets transmitted, 0 packets received, 100% packet loss
root@mx2_re> ping 1.1.1.1
PING 1.1.1.1 (1.1.1.1): 56 data bytes
64 bytes from 1.1.1.1: icmp_seq=0 ttl=63 time=3.171 ms
64 bytes from 1.1.1.1: icmp_seq=1 ttl=63 time=14.114 ms
^C
--- 1.1.1.1 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max/stddev = 3.171/8.643/14.114/5.472 msThere is a difference!
Traffic to RE (10.10.10.10) is blocked while transit traffic is allowed.
This is because filter is now applied to lo0 interface so it affects traffic destined to RE only.
Through this mechanism we can build a more granular Protect-RE filter.
Why more granular?
Look at our example. With a standard Protect-RE filter, we would block any icmp traffic reaching the RE. Here instead, we can decide to block only icmp traffic coming from specific interfaces (based on configured groups). Same goes for routing protocols and anything else. Moreover, we can decide that some interfaces are “trusted” and allow anything coming from there (here, interface ge-0/0/2 from MX3).
Is this the way to go to build our Protect-RE filter? As usual, it depends on the context and the requisites…but, as usual, it is important to know al the options we have in order to pick the best one for our given scenario.
Ciao
IoSonoUmberto