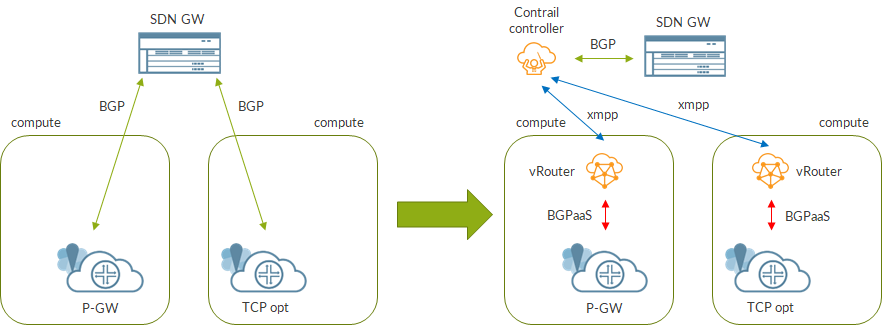
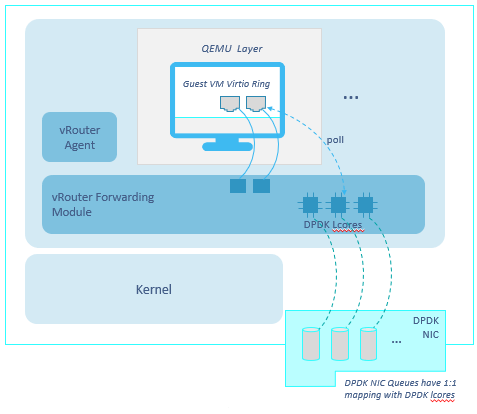
We are constantly looking for better performance. That allows to better utilize our infrastructure and to provide a faster service to end users.
The same is true for virtual environments like data centers running Openstack.
A first performance boost is given by using DPDK instead of a standard kernel based solution.
Anyhow, this is not enough! DPDK is faster but DPDK itself can be optimized.
I have already talked about setting up the right DPDK environment for Contrail (coremask, bond policy, encapsulation, etc…) in other posts but, recently (end of 2019) a new possibility emerged.
As of today, we were used to divide our cpu cores as follows:

Contrail vRouter is assigned some cores so that packet forwarding has dedicated resources that no one else can “touch”. Next, we have cores dedicated to Nova virtual machines; this way we are sure that only virtual machines will use those cores, avoiding possible pollution. Last, we have cores dedicated to standard OS processes (for instance, host OS ntp process).
Actually, here, we also have some cores that are totally unused: no one (vrouter, virtual machines, host OS) will touch them. Is this a waste? Probably yes but let’s accept it 😊
If we connect to a dpdk compute node we can easily identify the PID of the vrouter dpdk process:
[root@cpt7-dpdk-tovb-nbp ~]# ps -ef | grep dpdk
root 481592 481354 99 17:48 ? 01:31:35 /usr/bin/contrail-vrouter-dpdk --no-daemon --socket-mem 1024 1024 --vlan_tci 1074 --vlan_fwd_intf_name bond2 --vdev eth_bond_bond2,mode=4,xmit_policy=l34,socket_id=0,mac=48:df:37:3e:a8:44,lacp_rate=1,slave=0000:04:00.0,slave=0000:05:00.0
Once we have that value, we can check all the processes associated to it:
[root@cpt7-dpdk-tovb-nbp ~]# pidstat -t -p 481592
Linux 3.10.0-1062.4.1.el7.x86_64 (cpt7-dpdk-tovb-nbp) 01/10/2020 _x86_64_ (56 CPU)
06:11:26 PM UID TGID TID %usr %system %guest %CPU CPU Command
06:11:26 PM 0 481592 - 0.18 0.11 0.00 0.29 43 contrail-vroute
06:11:26 PM 0 - 481592 0.00 0.00 0.00 0.00 43 |__contrail-vroute
06:11:26 PM 0 - 481605 0.00 0.00 0.00 0.00 3 |__rte_mp_handle
06:11:26 PM 0 - 481606 0.00 0.00 0.00 0.00 3 |__rte_mp_async
06:11:26 PM 0 - 481614 0.00 0.00 0.00 0.00 15 |__eal-intr-thread
06:11:26 PM 0 - 481615 0.00 0.00 0.00 0.00 15 |__lcore-slave-1
06:11:26 PM 0 - 481616 0.00 0.00 0.00 0.00 14 |__lcore-slave-2
06:11:26 PM 0 - 481617 0.00 0.00 0.00 0.00 28 |__lcore-slave-8
06:11:26 PM 0 - 481618 0.00 0.00 0.00 0.00 15 |__lcore-slave-9
06:11:26 PM 0 - 481619 0.04 0.03 0.00 0.07 1 |__lcore-slave-10
06:11:26 PM 0 - 481620 0.04 0.03 0.00 0.07 2 |__lcore-slave-11
06:11:26 PM 0 - 481621 0.04 0.03 0.00 0.07 3 |__lcore-slave-12
06:11:26 PM 0 - 481622 0.04 0.03 0.00 0.07 4 |__lcore-slave-13
06:11:26 PM 0 - 482040 0.00 0.00 0.00 0.00 28 |__lcore-slave-9
Let’s start from lcores 10 to 13. Those are vrouter forwarding cores and, as you can see, they are pinned to cores 1-4. This comes from the configured dpdk core mask:
[root@cpt7-dpdk-tovb-nbp ~]# cat /etc/sysconfig/network-scripts/ifcfg-vhost0 | grep CPU
CPU_LIST=0x1E
You may notice that some processes (rte*) are using a vrouter forwarding thread. This comes from a dpdk bug that will be solved in newer releases. I will briefly talk about this later.
Anyhow, we also have lcores 1, 2, 8 and 9. Those cores are called service cores. This new optimization takes this second set of cores into consideration. Simply put, we will pin them as well.
As a consequence, our cpus layout will become:
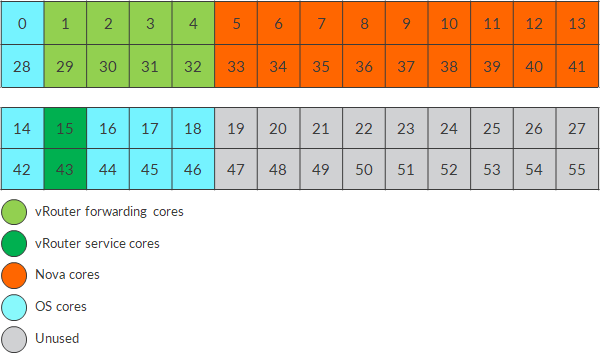
Some cores (1 physical core, 2 if considering hyperthreading) will be dedicated to vrouter service processes!
Now, we are going to see into details all these aspects and how to properly configure our setup.
Please, be aware that, right now, this is not an official procedure, not yet productized. Only use it in a lab environment for testing purposes! As we will see, procedure is not automated and affected by non-contrail bugs.
First, we have to be sure the environment is ready.
We are using a RHEL system and, in order to “isolate” cpus we do use the tuned utility:
[root@cpt7-dpdk-tovb-nbp ~]# tuned-adm active
Current active profile: cpu-partitioning
At the beginning, tuned configuration reflects this setup:
[root@cpt7-dpdk-tovb-nbp ~]# cat /etc/tuned/cpu-partitioning-variables.conf
isolated_cores=1-13,19-27,29-41,47-55
meaning host OS has these cores available:
[root@cpt7-dpdk-tovb-nbp ~]# cat /etc/systemd/system.conf | grep Affi
#CPUAffinity=1 2
CPUAffinity=0 14 15 16 17 18 28 42 43 44 45 46
I modify tuned configuration file as follows:
[root@cpt7-dpdk-tovb-nbp ~]# cat /etc/tuned/cpu-partitioning-variables.conf
isolated_cores=1-13,15,19-27,29-41,43,47-55
and re-apply the profile:
[root@cpt7-dpdk-tovb-nbp ~]# vi /etc/tuned/cpu-partitioning-variables.conf
[root@cpt7-dpdk-tovb-nbp ~]# tuned-adm profile cpu-partitioning
CONSOLE tuned.plugins.plugin_systemd: you may need to manualy run 'dracut -f' to update the systemd configuration in initrd image
As a result, host OS, will no longer use cores dedicated to vrouter service threads (15, 43):
[root@cpt7-dpdk-tovb-nbp ~]# cat /etc/systemd/system.conf | grep Affi
CPUAffinity=0 14 16 17 18 28 42 44 45 46
This can be confirmed this way:
[root@cpt7-dpdk-tovb-nbp ~]# taskset -pc 1
pid 1's current affinity list: 0,14,16-18,28,42,44-46
We already saw that before but I check vrouter forwarding cores mask is correct:
[root@cpt7-dpdk-tovb-nbp ~]# cat /etc/sysconfig/network-scripts/ifcfg-vhost0 | grep CPU
CPU_LIST=0x1E
Next, I verify nova pin set is right:
()[nova@cpt7-dpdk-tovb-nbp /]$ cat /etc/nova/nova.conf | grep pin_set
# vcpu_pin_set = "4-12,^8,15"
vcpu_pin_set=5-13,33-41
At this point we need to modify how the dpdk vrouter agent container is created.
This is managed by a function inside this file:
[root@cpt7-dpdk-tovb-nbp ~]# cat /etc/sysconfig/network-scripts/network-functions-vrouter-dpdk | grep -A 5 "docker run"
eval "docker run \
--detach \
--name ${container_name} \
--net host --privileged \
--restart always \
-v /etc/hosts:/etc/hosts:ro \
We need to add a line setting the “cpuset-cpus” parameter:
[root@cpt7-dpdk-tovb-nbp ~]# cat /etc/sysconfig/network-scripts/network-functions-vrouter-dpdk | grep -A 5 "docker run"
eval "docker run \
--detach \
--cpuset-cpus="0,1,2,3,4,14-18,28-32,42-46"\
--name ${container_name} \
--net host --privileged \
--restart always \
-v /etc/hosts:/etc/hosts:ro \
To trigger container re-creation with the new option I have to bring down/up vhost0:
[root@cpt7-dpdk-tovb-nbp ~]# ifdown vhost0
INFO: send SIGTERM to the container tim-contrail_containers-vrouter-agent-dpdk
tim-contrail_containers-vrouter-agent-dpdk
INFO: wait container tim-contrail_containers-vrouter-agent-dpdk finishes
0
INFO: send SIGTERM to the container tim-contrail_containers-vrouter-agent-dpdk
Error response from daemon: Cannot kill container tim-contrail_containers-vrouter-agent-dpdk: Container 062d999e9af99d3c3009104166bcb529f991c59e42295c3fc537cbbeef20bb2d is not running
INFO: wait container tim-contrail_containers-vrouter-agent-dpdk finishes
0
INFO: remove the container tim-contrail_containers-vrouter-agent-dpdk
tim-contrail_containers-vrouter-agent-dpdk
INFO: rebind device 0000:04:00.0 from vfio-pci to driver ixgbe
INFO: unbind 0000:04:00.0 from vfio-pci
INFO: bind 0000:04:00.0 to ixgbe
INFO: rebind device 0000:05:00.0 from vfio-pci to driver ixgbe
INFO: unbind 0000:05:00.0 from vfio-pci
INFO: bind 0000:05:00.0 to ixgbe
INFO: restore bind interface bond2
/etc/sysconfig/network-scripts /etc/sysconfig/network-scripts
/etc/sysconfig/network-scripts
[root@cpt7-dpdk-tovb-nbp ~]# ifup vhost0
8892db315c5188785a3500c236812a5636349a59bef20977258a14106b9abc1a
INFO: wait DPDK agent to run... 1
INFO: wait DPDK agent to run... 2
INFO: wait vhost0 to be initilaized... 0/60
INFO: wait vhost0 to be initilaized... 1/60
INFO: wait vhost0 to be initilaized... 2/60
INFO: vhost0 is ready.
RTNETLINK answers: File exists
RTNETLINK answers: File exists
RTNETLINK answers: File exists
RTNETLINK answers: File exists
We check the new property was taken into consideration:
[root@cpt7-dpdk-tovb-nbp ~]# docker inspect 8892db3 | grep CpusetCpus
"CpusetCpus": "0,1,2,3,4,14-18,28-32,42-46",
Everything looks alright!
Now it is time to pin service cores!
Let’s check again current pinning:
[root@cpt7-dpdk-tovb-nbp ~]# pidstat -t -p 481592
Linux 3.10.0-1062.4.1.el7.x86_64 (cpt7-dpdk-tovb-nbp) 01/10/2020 _x86_64_ (56 CPU)
06:11:26 PM UID TGID TID %usr %system %guest %CPU CPU Command
06:11:26 PM 0 481592 - 0.18 0.11 0.00 0.29 43 contrail-vroute
06:11:26 PM 0 - 481592 0.00 0.00 0.00 0.00 43 |__contrail-vroute
06:11:26 PM 0 - 481605 0.00 0.00 0.00 0.00 3 |__rte_mp_handle
06:11:26 PM 0 - 481606 0.00 0.00 0.00 0.00 3 |__rte_mp_async
06:11:26 PM 0 - 481614 0.00 0.00 0.00 0.00 15 |__eal-intr-thread
06:11:26 PM 0 - 481615 0.00 0.00 0.00 0.00 15 |__lcore-slave-1
06:11:26 PM 0 - 481616 0.00 0.00 0.00 0.00 14 |__lcore-slave-2
06:11:26 PM 0 - 481617 0.00 0.00 0.00 0.00 28 |__lcore-slave-8
06:11:26 PM 0 - 481618 0.00 0.00 0.00 0.00 15 |__lcore-slave-9
06:11:26 PM 0 - 481619 0.04 0.03 0.00 0.07 1 |__lcore-slave-10
06:11:26 PM 0 - 481620 0.04 0.03 0.00 0.07 2 |__lcore-slave-11
06:11:26 PM 0 - 481621 0.04 0.03 0.00 0.07 3 |__lcore-slave-12
06:11:26 PM 0 - 481622 0.04 0.03 0.00 0.07 4 |__lcore-slave-13
06:11:26 PM 0 - 482040 0.00 0.00 0.00 0.00 28 |__lcore-slave-9
Right now, what matters is that forwarding cores are consistent with vhost0 coremask.
This is also confirmed via this command:
[root@cpt7-dpdk-tovb-nbp ~]# taskset -cp -a 481592
pid 481592's current affinity list: 0-4,14-18,28-32,42-46
pid 481605's current affinity list: 3,4,14-18,28-32,42-46
pid 481606's current affinity list: 3,4,14-18,28-32,42-46
pid 481614's current affinity list: 3,4,14-18,28-32,42-46
pid 481615's current affinity list: 0-4,14-18,28-32,42-46
pid 481616's current affinity list: 0-4,14-18,28-32,42-46
pid 481617's current affinity list: 0-4,14-18,28-32,42-46
pid 481618's current affinity list: 0-4,14-18,28-32,42-46
pid 481619's current affinity list: 1
pid 481620's current affinity list: 2
pid 481621's current affinity list: 3
pid 481622's current affinity list: 4
pid 482040's current affinity list: 0-4,14-18,28-32,42-46
Only forwarding cores are pinned to a specific cores; service threads are currently not pinned.
Please notice PIDs 481605 and 481606. Those are rte* processes. As pointed out before, they are using vrouter forwarding cores. Those are standard dpdk control cores and should not use datapath cores. Anyhow, right now, due to a dpdk library bug, we do not have full control on how control threads can be pinned.
This Bugzilla is related to this issue https://bugzilla.redhat.com/show_bug.cgi?id=1687316 and will be fixed in future releases.
Potentially, this represents a pollution that might impact performance. However, “rumors” say this did not happen during tests.
And here comes the most important part: we ping service cores.
This is done via taskset:
taskset -cp 15 481615
taskset -cp 15 481616
taskset -cp 15 481617
taskset -cp 15 481618
taskset -cp 15 481592
taskset -cp 15 482040
We do also pin the main dpdk vrouter PID.
I did run those commands via a shell script:
[root@cpt7-dpdk-tovb-nbp ~]# sh setupsvconly.sh
pid 481615's current affinity list: 0-4,14-18,28-32,42-46
pid 481615's new affinity list: 15
pid 481616's current affinity list: 0-4,14-18,28-32,42-46
pid 481616's new affinity list: 15
pid 481617's current affinity list: 0-4,14-18,28-32,42-46
pid 481617's new affinity list: 15
pid 481618's current affinity list: 0-4,14-18,28-32,42-46
pid 481618's new affinity list: 15
pid 481592's current affinity list: 0-4,14-18,28-32,42-46
pid 481592's new affinity list: 15
pid 482040's current affinity list: 0-4,14-18,28-32,42-46
pid 482040's new affinity list: 15
As a result, we expect those cores to be assigned to 15:
[root@cpt7-dpdk-tovb-nbp ~]# pidstat -t -p 481592
Linux 3.10.0-1062.4.1.el7.x86_64 (cpt7-dpdk-tovb-nbp) 01/10/2020 _x86_64_ (56 CPU)
06:18:09 PM UID TGID TID %usr %system %guest %CPU CPU Command
06:18:09 PM 0 481592 - 0.23 0.15 0.00 0.37 15 contrail-vroute
06:18:09 PM 0 - 481592 0.00 0.00 0.00 0.00 15 |__contrail-vroute
06:18:09 PM 0 - 481605 0.00 0.00 0.00 0.00 3 |__rte_mp_handle
06:18:09 PM 0 - 481606 0.00 0.00 0.00 0.00 3 |__rte_mp_async
06:18:09 PM 0 - 481614 0.00 0.00 0.00 0.00 15 |__eal-intr-thread
06:18:09 PM 0 - 481615 0.00 0.00 0.00 0.00 15 |__lcore-slave-1
06:18:09 PM 0 - 481616 0.00 0.00 0.00 0.00 15 |__lcore-slave-2
06:18:09 PM 0 - 481617 0.00 0.00 0.00 0.00 15 |__lcore-slave-8
06:18:09 PM 0 - 481618 0.00 0.00 0.00 0.00 15 |__lcore-slave-9
06:18:09 PM 0 - 481619 0.06 0.04 0.00 0.09 1 |__lcore-slave-10
06:18:09 PM 0 - 481620 0.06 0.04 0.00 0.09 2 |__lcore-slave-11
06:18:09 PM 0 - 481621 0.06 0.04 0.00 0.09 3 |__lcore-slave-12
06:18:09 PM 0 - 481622 0.06 0.04 0.00 0.09 4 |__lcore-slave-13
[root@cpt7-dpdk-tovb-nbp ~]# taskset -cp -a 481592
pid 481592's current affinity list: 15
pid 481605's current affinity list: 3,4,14-18,28-32,42-46
pid 481606's current affinity list: 3,4,14-18,28-32,42-46
pid 481614's current affinity list: 3,4,14-18,28-32,42-46
pid 481615's current affinity list: 15
pid 481616's current affinity list: 15
pid 481617's current affinity list: 15
pid 481618's current affinity list: 15
pid 481619's current affinity list: 1
pid 481620's current affinity list: 2
pid 481621's current affinity list: 3
pid 481622's current affinity list: 4
pid 482040's current affinity list: 15
Optionally, we can pin control threads as well (rte* and eal):
[root@cpt7-dpdk-tovb-nbp ~]# sh setupall.sh
pid 481605's current affinity list: 3,4,14-18,28-32,42-46
pid 481605's new affinity list: 0,14,16-18,28,42,44-46
pid 481606's current affinity list: 3,4,14-18,28-32,42-46
pid 481606's new affinity list: 0,14,16-18,28,42,44-46
pid 481614's current affinity list: 3,4,14-18,28-32,42-46
pid 481614's new affinity list: 0,14,16-18,28,42,44-46
pid 481615's current affinity list: 15
pid 481615's new affinity list: 15
pid 481616's current affinity list: 15
pid 481616's new affinity list: 15
pid 481617's current affinity list: 15
pid 481617's new affinity list: 15
pid 481618's current affinity list: 15
pid 481618's new affinity list: 15
pid 481592's current affinity list: 15
pid 481592's new affinity list: 15
pid 482040's current affinity list: 15
pid 482040's new affinity list: 15
but, due to the dpdk bug, result is not as good as expected:
[root@cpt7-dpdk-tovb-nbp ~]# pidstat -t -p 481592
Linux 3.10.0-1062.4.1.el7.x86_64 (cpt7-dpdk-tovb-nbp) 01/10/2020 _x86_64_ (56 CPU)
06:20:04 PM UID TGID TID %usr %system %guest %CPU CPU Command
06:20:04 PM 0 481592 - 0.24 0.16 0.00 0.40 15 contrail-vroute
06:20:04 PM 0 - 481592 0.00 0.00 0.00 0.00 15 |__contrail-vroute
06:20:04 PM 0 - 481605 0.00 0.00 0.00 0.00 3 |__rte_mp_handle
06:20:04 PM 0 - 481606 0.00 0.00 0.00 0.00 3 |__rte_mp_async
06:20:04 PM 0 - 481614 0.00 0.00 0.00 0.00 16 |__eal-intr-thread
06:20:04 PM 0 - 481615 0.00 0.00 0.00 0.00 15 |__lcore-slave-1
06:20:04 PM 0 - 481616 0.00 0.00 0.00 0.00 15 |__lcore-slave-2
06:20:04 PM 0 - 481617 0.00 0.00 0.00 0.00 15 |__lcore-slave-8
06:20:04 PM 0 - 481618 0.00 0.00 0.00 0.00 15 |__lcore-slave-9
06:20:04 PM 0 - 481619 0.06 0.04 0.00 0.10 1 |__lcore-slave-10
06:20:04 PM 0 - 481620 0.06 0.04 0.00 0.10 2 |__lcore-slave-11
06:20:04 PM 0 - 481621 0.06 0.04 0.00 0.10 3 |__lcore-slave-12
06:20:04 PM 0 - 481622 0.06 0.04 0.00 0.10 4 |__lcore-slave-13
06:20:04 PM 0 - 482040 0.00 0.00 0.00 0.00 28 |__lcore-slave-9
[root@cpt7-dpdk-tovb-nbp ~]# taskset -cp -a 481592
pid 481592's current affinity list: 15
pid 481605's current affinity list: 0,14,16-18,28,42,44-46
pid 481606's current affinity list: 0,14,16-18,28,42,44-46
pid 481614's current affinity list: 0,14,16-18,28,42,44-46
pid 481615's current affinity list: 15
pid 481616's current affinity list: 15
pid 481617's current affinity list: 15
pid 481618's current affinity list: 15
pid 481619's current affinity list: 1
pid 481620's current affinity list: 2
pid 481621's current affinity list: 3
pid 481622's current affinity list: 4
pid 482040's current affinity list: 15
Some control threads (rte*) run on cpu 3 even if that cpu is not included in the affinity list of those processes.
Anyhow, control threads are not as important as service ones.
Pinning service cores should increase performance.
However, as we have just seen, at the moment, the process is pretty manual and time-consuming.
Moreover, as taskset commands reference the current PID of a process, if a dpdk vrouter agent is brought down (ifdown/ifup vhost0), service cores pinning will need to be re-done as there will be new PIDs into play.
Future contrail releases will overcome this by allowing to set a sort of second coremask used to pin service cores. This will make the whole pinning process automated and consistent across dpdk vrouter agent restarts 😊
Check if your performance actually groes!
Ciao
IoSonoUmberto